













- Joined
- Nov 26, 2020
- Messages
- 716
I've always been bothered by the way Google AdSense compulsively served contextual ads based on my old search queries. It seems that quite a lot of time has passed since the search, and cookies and browser cache were cleared more than once, but ads remained. How did they keep tracking me? It turns out that there are plenty of ways to do this.
Short introduction
User identification, tracking, or simply web tracking involves calculating and setting a unique identifier for each browser that visits a particular site. In General, initially it was not intended as some kind of universal evil and, like everything else, has a reverse side, that is, it is designed to bring benefits. For example, allow site owners to distinguish regular users from bots, or provide the ability to store user preferences and apply them during a subsequent session. But at the same time, the advertising industry really liked this opportunity. As you well know, cookies are one of the most popular ways to identify users. And they have been actively used in the advertising industry since the mid-nineties.
Since then, a lot has changed, technology has gone far ahead, and currently tracking users with cookies alone is not limited. In fact, there are many ways to identify users. The most obvious option is to set some identifiers, such as cookies. The next option is to use data about the PC used by the user, which can be obtained from the HTTP headers of sent requests: address, type of OS used, time, and so on. Finally, you can distinguish the user by their behavior and habits (cursor movements, favorite sections of the site, and so on).
Explicit identifiers
This approach is quite obvious. all that is required is to store some long-lived identifier on the user's side, which can be requested during a subsequent visit to the resource. Modern browsers provide enough ways to do this transparently for the user. First of all, these are good old cookies. Then there are the features of some plugins that are similar in functionality to cookies, for exampleLocal Shared Objects, in flash or Isolated StorageSilverlight. HTML5 also includes several client-side storage mechanisms, includinglocalStorage, Fileand IndexedDB API. In addition to these locations, unique tokens can also be stored in cached resources on the local machine or cache metadata (Last-Modified,ETag). In addition, you can identify the user by using fingerprints obtained from Origin Bound certificates generated by the browser for SSL connections, data contained in SDCH dictionaries, and metadata from these dictionaries. In a word, there are plenty of opportunities.
Cookies
When it comes to storing some small amount of data on the client side, cookies are the first thing that usually comes to mind. the Web server sets a unique identifier for the new user, storing it in cookies, and for all subsequent requests, the client will send it to the server. Although all popular browsers have long been equipped with a user-friendly interface for managing cookies, and the Network is full of third-party utilities for managing them and blocking them, cookies are still actively used for tracking users. The fact is that very few people view and clean them (remember the last time you did this). Perhaps the main reason for this is that everyone is afraid to accidentally delete the necessary "cookie", which, for example, can be used for authorization. Although some browsers allow you to restrict the installation of third-party cookies, the problem persists, since browsers often consider cookies received via HTTP redirects or other methods during page content loading to be" native". Unlike most of the mechanisms we'll discuss later, the use of cookies is transparent to the end user. In order to "mark" a user, it is not even necessary to store a unique identifier in a separate cookie - it can be collected from the values of several cookies or stored in metadata, such as Expiration Time. Therefore, at this stage, it is quite difficult to figure out whether a specific cookie is used for tracking or not.
Local Shared Objects
Adobe Flash uses the LSO mechanism to store data on the client side . It is an analog of cookies in HTTP, but unlike the latter, it can store not only short fragments of text data, which, in turn, complicates the analysis and verification of such objects. Before version 10.3, the behavior of flash cookies was configured separately from the browser settings: you had to visit the Flash settings Manager located on the site macromedia.com(by the way, it is still available at the following linkToday, this can be done directly from the control panel. In addition, most modern browsers provide fairly tight integration with the flash player: for example, when deleting cookies and other site data, lsos will also be deleted. On the other hand, the interaction of browsers with the player is still not so close, so setting the browser policy for third-party cookies will not always affect flash cookies (on the Adobe website, you can see how to manually disable them).
Deleting data from localstorage in Firefox.
Isolated Silverlight storage
The Silverlight software platform has quite a lot in common with Adobe Flash. So, an analog of Local Shared Objectsa flash drive is a mechanism called Isolated Storage. However, unlike the flash, the privacy settings here are not tied to the browser in any way, so even if the cookies and browser cache are completely cleared, the data stored in Isolated Storage, will still remain. But even more interesting is that the storage is shared by all browser Windows (except those opened in Incognito mode) and all profiles installed on the same machine. As with LSO, there are no technical barriers to storing session IDs. However, given that it is not yet possible to reach this mechanism through the browser settings, it has not become so widely used as a repository for unique identifiers.
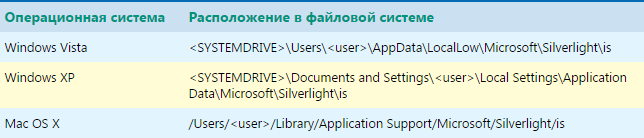
Where to look for isolated Silverlight storage
HTML5 and data storage on the client
HTML5 provides a set of mechanisms for storing structured data on the client. These include localStorage, the File API, and IndexedDB. Despite their differences, they are all designed to provide permanent storage of arbitrary chunks of binary data tied to a specific resource. Plus, unlike HTTP and Flash cookies, there are no significant restrictions on the size of stored data. In modern browsers, the HTML5 storage is located along with other site data. However, it is very difficult to guess how to manage the storage via the browser settings. For example, to delete data from localStorage in Firefox, the user will have to choose offline website data or site preferences and set the time interval to everything. Another unusual feature that is unique to IE is that data exists only for the lifetime of tabs opened at the time of saving them. Plus, the above mechanisms don't really try to follow the restrictions that apply to HTTP cookies. For example, you can write to localStorageand read from it via cross-domain frames, even if third-party cookies are disabled.
Configuring local storage for Flash Player.
Cached objects
Everyone wants the browser to work fast and without brakes. Therefore, it has to store the resources of the visited sites in the local cache (so as not to request them during a subsequent session). Although this mechanism was clearly not intended to be used as a random access storage, it can be turned into one. For example, the server can return a JavaScript document to the user with a unique identifier inside its body and set it in the headers Expires / max-age= the distant future. This way, the script and its unique identifier will be stored in the browser cache. After that, it can be accessed from any page on the Network, simply by requesting the script to be downloaded from a known URL. Of course, the browser will periodically use the header to ask If-Modified-Sinceif a new version of the script is available. But if the server returns the 304 code (Not modified), then the cached copy will be used forever. What else is interesting about the cache? There is no concept of "third-party" objects, as, for example, in the case of HTTP cookies. At the same time, disabling caching can seriously affect performance. And automatic detection of tricky resources that store some identifiers/tags is difficult due to the large volume and complexity of JavaScript documents found on the Web. Of course, all browsers allow the user to manually clear the cache. But as practice shows (even our own example), this is not done so often, if at all.
ETag and Last-Modified
In order for caching to work correctly, the server must somehow inform the browser that a newer version of the document is available. The HTTP / 1.1 standard offers two ways to solve this problem. The first is based on the date when the document was last modified, and the second is based on an abstract identifier known as ETag. In the case of CETag, the server initially returns the so-called version tag in the response header along with the document itself. For subsequent requests to the specified URL, the client informs the server via the header If-None-Match this is the value associated with its local copy. If the version specified in this header is up-to-date, the server responds with the 304 (Not Modified) HTTP code, and the client can safely use the cached version. Otherwise, the server sends a new version of the document with a new ETagone . This approach is somewhat similar to HTTP cookies — the server stores an arbitrary value on the client only to read it later. Another method, using a headerLast-Modified, allows you to store at least 32 bits of data in a date string, which is then sent by the client to the server in the header If-Modified-Since. Interestingly, most browsers don't even require this string to represent a date in the correct format. Just like in the case of user identification via cached objects, ETagand Last-Modifiedis not affected in any way by deleting cookies and site data.you can only get rid of them by clearing the cache.
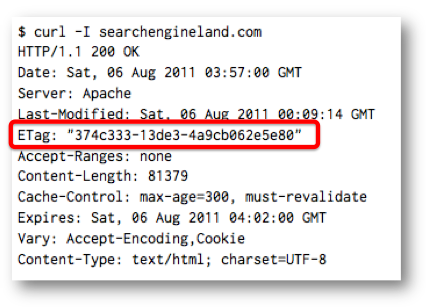
The server returns an ETag to the client
HTML5 AppCache
Application Cache allows you to specify which part of the site should be saved to disk and be accessible, even if the user is offline. All controlled with manifests that specify the rules for the storage and retrieval of elements in the cache. Similar to the traditional caching mechanism, AppCache also allows you to store unique, user-specific data-both inside the manifest itself and inside resources that are stored indefinitely (unlike a regular cache, resources from which are deleted after some time). AppCache occupies an intermediate value between the HTML5 data storage mechanisms and the normal browser cache. In some browsers, it is cleared when cookies and site data are deleted, while in others, it is only cleared when browsing history and all cached documents are deleted.
SDCH dictionaries
SDCH is a compression algorithm developed by Google that uses the dictionaries provided by the server and allows you to achieve a higher level of compression than Gzip or deflate. The fact is that in normal life, the web server returns too much repetitive information-page headers/footers, embedded JavaScript/CSS, and so on. In this approach, the client receives a dictionary file from the server containing strings that may appear in subsequent responses (the same headers/footers/JS/CSS). After that, the server can simply refer to these elements inside the dictionary, and the client will independently build the page based on them. As you can see, these dictionaries can easily be used to store unique identifiers, which can be placed both in the dictionary IDS returned by the client to the server in the headerAvail-Dictionary, and directly in the content itself. And then use it in the same way as in the case of a regular browser cache.
Other storage mechanisms
But this is not all the options. With the help of JavaScript and Its fellow developers, you can save and request a unique identifier so that it remains alive even after deleting the entire browsing history and site data. As one of the options, you can use it for storing window.nameor sessionStorage. Even if the user clears all cookies and site data, but does not close the tab where the tracking site was opened, the identification token will be received by the server on the next visit and the user will again be linked to the data already collected about him. The same behavior is observed in JS. any open JavaScript context retains its state, even if the user deletes the site data. At the same time, such JavaScript can not only belong to the displayed site, but also hide in iframes, web workers, and so on. For example, an ad loaded in an iframe will not pay any attention to deleting the site's browsing history and data, and will continue to use the ID stored in a local variable in JS.
Protocols
In addition to the mechanisms associated with caching, the use of JS and various plugins, modern browsers have several other network features that allow you to store and retrieve unique identifiers.
Machine specifications
All the methods considered before were based on the fact that the user was set a unique identifier, which was sent to the server during subsequent requests. There is another, less obvious approach to tracking users that relies on querying or measuring the characteristics of the client machine. Individually, each received characteristic represents only a few bits of information, but if you combine several of them, they can uniquely identify any computer on the Internet. In addition to the fact that such surveillance is much more difficult to detect and prevent, this technique will allow you to identify a user who is sitting under different browsers or using private mode.
Browser's "fingerprints"
The simplest approach to tracking is to build identifiers by combining a set of parameters available in the browser environment, each of which individually is not of any interest, but together they form a unique value for each machine:
Network " fingerprints»
A number of other features are found in the architecture of the local network and the configuration of network protocols. Such signs will be common for all browsers installed on the client machine, and they can't just be hidden using privacy settings or some security utilities. These include:
Behavioral analysis and habits
Another option is to look in the direction of characteristics that are not tied to the PC, but rather to the end user, such as regional settings and behavior. This method again allows you to identify clients between different browser sessions, profiles, and in the case of private browsing. You can draw conclusions based on the following data, which is always available for study:
To summarize
As you can see, in practice, there are a large number of different ways to track a user. Some of them are the result of implementation errors or omissions and can theoretically be corrected. Others are almost impossible to eradicate without completely changing the principles of computer networks, web applications, and browsers. You can counteract some techniques by clearing the cache, cookies, and other places where unique identifiers can be stored. Others work completely unnoticed by the user, and you are unlikely to be able to protect yourself from them. Therefore, the most important thing is to travel around the Network, even in private viewing mode, remember that your movements can still be tracked.
Short introduction
User identification, tracking, or simply web tracking involves calculating and setting a unique identifier for each browser that visits a particular site. In General, initially it was not intended as some kind of universal evil and, like everything else, has a reverse side, that is, it is designed to bring benefits. For example, allow site owners to distinguish regular users from bots, or provide the ability to store user preferences and apply them during a subsequent session. But at the same time, the advertising industry really liked this opportunity. As you well know, cookies are one of the most popular ways to identify users. And they have been actively used in the advertising industry since the mid-nineties.
Since then, a lot has changed, technology has gone far ahead, and currently tracking users with cookies alone is not limited. In fact, there are many ways to identify users. The most obvious option is to set some identifiers, such as cookies. The next option is to use data about the PC used by the user, which can be obtained from the HTTP headers of sent requests: address, type of OS used, time, and so on. Finally, you can distinguish the user by their behavior and habits (cursor movements, favorite sections of the site, and so on).
Explicit identifiers
This approach is quite obvious. all that is required is to store some long-lived identifier on the user's side, which can be requested during a subsequent visit to the resource. Modern browsers provide enough ways to do this transparently for the user. First of all, these are good old cookies. Then there are the features of some plugins that are similar in functionality to cookies, for exampleLocal Shared Objects, in flash or Isolated StorageSilverlight. HTML5 also includes several client-side storage mechanisms, includinglocalStorage, Fileand IndexedDB API. In addition to these locations, unique tokens can also be stored in cached resources on the local machine or cache metadata (Last-Modified,ETag). In addition, you can identify the user by using fingerprints obtained from Origin Bound certificates generated by the browser for SSL connections, data contained in SDCH dictionaries, and metadata from these dictionaries. In a word, there are plenty of opportunities.
Cookies
When it comes to storing some small amount of data on the client side, cookies are the first thing that usually comes to mind. the Web server sets a unique identifier for the new user, storing it in cookies, and for all subsequent requests, the client will send it to the server. Although all popular browsers have long been equipped with a user-friendly interface for managing cookies, and the Network is full of third-party utilities for managing them and blocking them, cookies are still actively used for tracking users. The fact is that very few people view and clean them (remember the last time you did this). Perhaps the main reason for this is that everyone is afraid to accidentally delete the necessary "cookie", which, for example, can be used for authorization. Although some browsers allow you to restrict the installation of third-party cookies, the problem persists, since browsers often consider cookies received via HTTP redirects or other methods during page content loading to be" native". Unlike most of the mechanisms we'll discuss later, the use of cookies is transparent to the end user. In order to "mark" a user, it is not even necessary to store a unique identifier in a separate cookie - it can be collected from the values of several cookies or stored in metadata, such as Expiration Time. Therefore, at this stage, it is quite difficult to figure out whether a specific cookie is used for tracking or not.
Local Shared Objects
Adobe Flash uses the LSO mechanism to store data on the client side . It is an analog of cookies in HTTP, but unlike the latter, it can store not only short fragments of text data, which, in turn, complicates the analysis and verification of such objects. Before version 10.3, the behavior of flash cookies was configured separately from the browser settings: you had to visit the Flash settings Manager located on the site macromedia.com(by the way, it is still available at the following linkToday, this can be done directly from the control panel. In addition, most modern browsers provide fairly tight integration with the flash player: for example, when deleting cookies and other site data, lsos will also be deleted. On the other hand, the interaction of browsers with the player is still not so close, so setting the browser policy for third-party cookies will not always affect flash cookies (on the Adobe website, you can see how to manually disable them).
Deleting data from localstorage in Firefox.
Isolated Silverlight storage
The Silverlight software platform has quite a lot in common with Adobe Flash. So, an analog of Local Shared Objectsa flash drive is a mechanism called Isolated Storage. However, unlike the flash, the privacy settings here are not tied to the browser in any way, so even if the cookies and browser cache are completely cleared, the data stored in Isolated Storage, will still remain. But even more interesting is that the storage is shared by all browser Windows (except those opened in Incognito mode) and all profiles installed on the same machine. As with LSO, there are no technical barriers to storing session IDs. However, given that it is not yet possible to reach this mechanism through the browser settings, it has not become so widely used as a repository for unique identifiers.
Where to look for isolated Silverlight storage
HTML5 and data storage on the client
HTML5 provides a set of mechanisms for storing structured data on the client. These include localStorage, the File API, and IndexedDB. Despite their differences, they are all designed to provide permanent storage of arbitrary chunks of binary data tied to a specific resource. Plus, unlike HTTP and Flash cookies, there are no significant restrictions on the size of stored data. In modern browsers, the HTML5 storage is located along with other site data. However, it is very difficult to guess how to manage the storage via the browser settings. For example, to delete data from localStorage in Firefox, the user will have to choose offline website data or site preferences and set the time interval to everything. Another unusual feature that is unique to IE is that data exists only for the lifetime of tabs opened at the time of saving them. Plus, the above mechanisms don't really try to follow the restrictions that apply to HTTP cookies. For example, you can write to localStorageand read from it via cross-domain frames, even if third-party cookies are disabled.
Configuring local storage for Flash Player.
Cached objects
Everyone wants the browser to work fast and without brakes. Therefore, it has to store the resources of the visited sites in the local cache (so as not to request them during a subsequent session). Although this mechanism was clearly not intended to be used as a random access storage, it can be turned into one. For example, the server can return a JavaScript document to the user with a unique identifier inside its body and set it in the headers Expires / max-age= the distant future. This way, the script and its unique identifier will be stored in the browser cache. After that, it can be accessed from any page on the Network, simply by requesting the script to be downloaded from a known URL. Of course, the browser will periodically use the header to ask If-Modified-Sinceif a new version of the script is available. But if the server returns the 304 code (Not modified), then the cached copy will be used forever. What else is interesting about the cache? There is no concept of "third-party" objects, as, for example, in the case of HTTP cookies. At the same time, disabling caching can seriously affect performance. And automatic detection of tricky resources that store some identifiers/tags is difficult due to the large volume and complexity of JavaScript documents found on the Web. Of course, all browsers allow the user to manually clear the cache. But as practice shows (even our own example), this is not done so often, if at all.
ETag and Last-Modified
In order for caching to work correctly, the server must somehow inform the browser that a newer version of the document is available. The HTTP / 1.1 standard offers two ways to solve this problem. The first is based on the date when the document was last modified, and the second is based on an abstract identifier known as ETag. In the case of CETag, the server initially returns the so-called version tag in the response header along with the document itself. For subsequent requests to the specified URL, the client informs the server via the header If-None-Match this is the value associated with its local copy. If the version specified in this header is up-to-date, the server responds with the 304 (Not Modified) HTTP code, and the client can safely use the cached version. Otherwise, the server sends a new version of the document with a new ETagone . This approach is somewhat similar to HTTP cookies — the server stores an arbitrary value on the client only to read it later. Another method, using a headerLast-Modified, allows you to store at least 32 bits of data in a date string, which is then sent by the client to the server in the header If-Modified-Since. Interestingly, most browsers don't even require this string to represent a date in the correct format. Just like in the case of user identification via cached objects, ETagand Last-Modifiedis not affected in any way by deleting cookies and site data.you can only get rid of them by clearing the cache.
The server returns an ETag to the client
HTML5 AppCache
Application Cache allows you to specify which part of the site should be saved to disk and be accessible, even if the user is offline. All controlled with manifests that specify the rules for the storage and retrieval of elements in the cache. Similar to the traditional caching mechanism, AppCache also allows you to store unique, user-specific data-both inside the manifest itself and inside resources that are stored indefinitely (unlike a regular cache, resources from which are deleted after some time). AppCache occupies an intermediate value between the HTML5 data storage mechanisms and the normal browser cache. In some browsers, it is cleared when cookies and site data are deleted, while in others, it is only cleared when browsing history and all cached documents are deleted.
SDCH dictionaries
SDCH is a compression algorithm developed by Google that uses the dictionaries provided by the server and allows you to achieve a higher level of compression than Gzip or deflate. The fact is that in normal life, the web server returns too much repetitive information-page headers/footers, embedded JavaScript/CSS, and so on. In this approach, the client receives a dictionary file from the server containing strings that may appear in subsequent responses (the same headers/footers/JS/CSS). After that, the server can simply refer to these elements inside the dictionary, and the client will independently build the page based on them. As you can see, these dictionaries can easily be used to store unique identifiers, which can be placed both in the dictionary IDS returned by the client to the server in the headerAvail-Dictionary, and directly in the content itself. And then use it in the same way as in the case of a regular browser cache.
Other storage mechanisms
But this is not all the options. With the help of JavaScript and Its fellow developers, you can save and request a unique identifier so that it remains alive even after deleting the entire browsing history and site data. As one of the options, you can use it for storing window.nameor sessionStorage. Even if the user clears all cookies and site data, but does not close the tab where the tracking site was opened, the identification token will be received by the server on the next visit and the user will again be linked to the data already collected about him. The same behavior is observed in JS. any open JavaScript context retains its state, even if the user deletes the site data. At the same time, such JavaScript can not only belong to the displayed site, but also hide in iframes, web workers, and so on. For example, an ad loaded in an iframe will not pay any attention to deleting the site's browsing history and data, and will continue to use the ID stored in a local variable in JS.
Protocols
In addition to the mechanisms associated with caching, the use of JS and various plugins, modern browsers have several other network features that allow you to store and retrieve unique identifiers.
- Origin Bound Certificates aka ChannelID) - persistent self-signed certificates that identify the client to the HTTPS server. For each new domain, a separate certificate is created, which is used for connections initiated later. Sites can use OBC to track users without taking any actions that will be visible to the client. As a unique identifier, you can use the cryptographic hash of the certificate provided by the client as part of a legitimate SSL handshake.
- Similarly, TLS also has two mechanisms-session identifiersandsession tickets, which allow clients to resume interrupted HTTPS connections without performing a full handshake. This is achieved by using cached data. These two mechanisms allow servers to identify requests originating from a single client over a short period of time.
- Almost all modern browsers implement their own internal DNS cache to speed up the name resolution process (and in some cases reduce the risk of DNS rebinding attacks). This cache can easily be used to store small amounts of information. For example, if you have 16 available IP addresses, about 8-9 cached names will be enough to identify each computer on the Network. However, this approach is limited by the size of the browsers ' internal DNS cache and can potentially lead to name resolution conflicts with the provider's DNS.
Machine specifications
All the methods considered before were based on the fact that the user was set a unique identifier, which was sent to the server during subsequent requests. There is another, less obvious approach to tracking users that relies on querying or measuring the characteristics of the client machine. Individually, each received characteristic represents only a few bits of information, but if you combine several of them, they can uniquely identify any computer on the Internet. In addition to the fact that such surveillance is much more difficult to detect and prevent, this technique will allow you to identify a user who is sitting under different browsers or using private mode.
Browser's "fingerprints"
The simplest approach to tracking is to build identifiers by combining a set of parameters available in the browser environment, each of which individually is not of any interest, but together they form a unique value for each machine:
- User-Agent. Returns the browser version, OS version, and some of the installed Addons. In cases where the User-Agent is missing or you want to check its "veracity", you can determine the browser version by checking for certain features implemented or changed between releases.
- Clock running. If the system does not synchronize its clock with a third-party time server, then sooner or later it will start to lag or rush, which will create a unique difference between real and system time, which can be measured with microsecond accuracy using JavaScript. In fact, even when syncing with an NTP server, there will still be small deviations that can also be measured.
- Information about CPU and GPU. You can get it either directly (via GL_RENDERER), or through benchmarks and tests implemented using JavaScript.
- Monitor resolution and browser window size (including parameters of the second monitor in the case of a multi-monitor system).
- A list of fonts installed in the system, obtained, for example, using getComputedStylethe API.
- A list of all installed plugins, ActiveX controls, and Browser Helper Objects, including their versions. You can get it by brutenavigator.plugins[]-force (some plugins show their presence in HTTP headers).
- Information about installed extensions and other SOFTWARE. Extensions such as ad blockers make certain changes to the pages viewed, which can be used to determine what kind of extension it is and its settings.
Network " fingerprints»
A number of other features are found in the architecture of the local network and the configuration of network protocols. Such signs will be common for all browsers installed on the client machine, and they can't just be hidden using privacy settings or some security utilities. These include:
- External IP address. For IPv6 addresses, this vector is particularly interesting, since in some cases the last octets can be obtained from the device's MAC address and therefore be preserved even when connected to different networks.
- Port numbers for outgoing TCP / IP connections (usually selected sequentially for most operating systems).
- Local IP address for users who are behind a NAT or HTTP proxy. Combined with an external IP address, it allows you to uniquely identify most of your customers.
- Information about the proxy servers used by the client, obtained from the HTTP header (X-Forwarded-For). In combination with the real address of the client, obtained through several possible ways to bypass the proxy also allows you to identify the user.
Behavioral analysis and habits
Another option is to look in the direction of characteristics that are not tied to the PC, but rather to the end user, such as regional settings and behavior. This method again allows you to identify clients between different browser sessions, profiles, and in the case of private browsing. You can draw conclusions based on the following data, which is always available for study:
- Preferred language, default encoding, and time zone (all of this lives in HTTP headers and is accessible from JavaScript).
- Data in the client's cache and its browsing history. Cache elements can be detected using time-based attacks - the tracker can detect long-lived cache elements related to popular resources by simply measuring the time from loading (and canceling the transition if the time exceeds the expected load time from the local cache). You can also extract URLS stored in the browser's browsing history, although such an attack in modern browsers will require little user interaction.
- Mouse gestures, the frequency and duration of keystrokes, and data from the accelerometer - all these parameters are unique for each user.
- Any changes to the site's standard fonts and their sizes, zoom level, and use of special features such as text color and size.
- The state of certain browser features configured by the client: blocking third-party cookies, DNS prefetching, blocking pop-UPS, Flash security settings, and so on (ironically, users who change the default settings actually make their browser much easier to identify).
To summarize
As you can see, in practice, there are a large number of different ways to track a user. Some of them are the result of implementation errors or omissions and can theoretically be corrected. Others are almost impossible to eradicate without completely changing the principles of computer networks, web applications, and browsers. You can counteract some techniques by clearing the cache, cookies, and other places where unique identifiers can be stored. Others work completely unnoticed by the user, and you are unlikely to be able to protect yourself from them. Therefore, the most important thing is to travel around the Network, even in private viewing mode, remember that your movements can still be tracked.